

Mit der robots.txt-Datei können Sie die Crawling-Effizienz Ihrer Website erheblich verbessern. Indem Sie präzise Anweisungen erteilen – beispielsweise mit einem einfachen Disallow: /private/ – verhindern Sie, dass Bots auf bestimmte Verzeichnisse zugreifen, die nicht indexiert werden sollen. Dies hilft Suchmaschinen, ihre Ressourcen effizient zu nutzen und sich auf die wirklich wichtigen Inhalte zu konzentrieren. Darüber hinaus können Sie spezifische Anweisungen für bestimmte Bots, wie den Googlebot, festlegen, um sicherzustellen, dass Ihre Präferenzen konsequent umgesetzt werden. Die robots.txt-Datei ist also nicht nur eine Empfehlung, sondern ein entscheidender Bestandteil Ihrer SEO-Strategie, der dazu beiträgt, Ihre Sichtbarkeit online zu optimieren. Nutzen Sie diese Möglichkeit, um den Erfolg Ihrer Website zu steigern und Ihr Unternehmen noch erfolgreicher im digitalen Raum zu positionieren.
Protokolle die in der Robots.txt Datei verwaltet werden
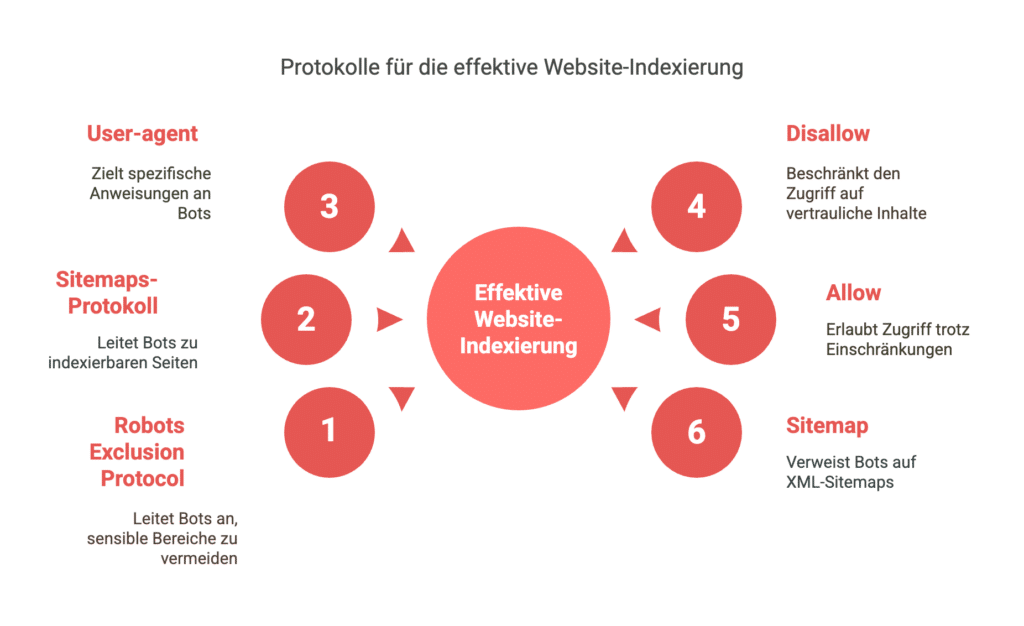
Die Verwaltung der robots.txt-Datei ist ein entscheidender Schritt, um effizient und kontrolliert die Indexierung Ihrer Website zu steuern. Indem Sie die folgenden Protokolle in Ihrer robots.txt-Datei verwenden, können Sie sicherstellen, dass Suchmaschinen-Bots Ihre Website optimal crawlen:
- Robots Exclusion Protocol: Hauptsächlich genutzt, um Bots zu signalisieren, welche Bereiche Ihrer Website sie vermeiden sollen. Dies hilft dabei, sensible oder irrelevante Inhalte von der Indexierung auszuschließen.
- Sitemaps-Protokoll: Ergänzt das Robots Exclusion Protocol, indem es als Robotereinschlussprotokoll fungiert. Es zeigt den Crawlern explizit, welche Seiten gecrawlt und indexiert werden dürfen.
- User-agent: Definieren Sie, für welchen Bot spezielle Anweisungen gedacht sind. Beispielsweise gilt
User-agent: *für alle Bots, währendUser-agent: Googlebotspezifisch für den Google-Bot ist. - Disallow: Blockieren Sie den Zugriff auf bestimmte Seiten oder Verzeichnisse, um vertrauliche Informationen zu schützen. Ein Beispiel könnte
Disallow: /private/sein, welches den Zugriff auf den privaten Ordner untersagt. - Allow: Erlaubt trotz vorheriger Blockierungen den Zugriff auf bestimmte Seiten oder Verzeichnisse, beispielsweise
Allow: /public/, das den Zugriff auf den öffentlichen Ordner gestattet, selbst wenn der übergeordnete Bereich blockiert ist. - Sitemap: Weisen Sie Bots auf die XML-Sitemap Ihrer Website hin, um eine umfassende und zielgerichtete Indexierung zu unterstützen. Eine typische Syntax könnte
Sitemap: https://www.example.com/sitemap.xmllauten.

Kann Noah als SEO Spezialisten wärmstens empfehlen. Er weiß wovon er spricht und ist im Online Marketing zu Hause. Top Leistung!
AUSGEZEICHNETTrustindex überprüft, ob die Originalquelle der Bewertung Google ist. Lutz Online Marketing in Düsseldorf ist als SEO Freelancer tätig. Als SEO Experte arbeitet er hoch professionell, er ist sehr erfahren und in vielen Branchen tätig. Er hat mich sehr erfolgreich bei meinem Online Marketing unterstützt. Herr Lutz ist äußerst zuverlässig und sehr zielorientiert, seine Leistung war sehr schnell erfolgreich. Ich kann Lutz Online Marketing uneingeschränkt empfehlen.Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Herr Lutz hat unser Unternehmen hervorragend beraten und uns in kurzer Zeit wichtige Tipps gegeben. Vielen Dank dafür!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Sehr empfehlenswerter SEO Freelancer aus Düsseldorf! Professionell, zuverlässig und immer auf dem neuesten Stand der Entwicklungen im Bereich Suchmaschinenoptimierung. Wir Arbeiten in mehreren Projekten mit Noah zusammen und von Beginn an hat sich die Sichtbarkeit massiv verbessert. Überzeugt hat uns von Anfang vor allem auch die maximale Transparenz sowie die sofortige Erreichbarkeit bei Fragen oder Gesprächsbedarf. Das ist Dienstleistung auf einem ganz hohen Niveau. Danke für die tolle Arbeit und wir freuen uns auf alles Weitere!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Noah konnte mir gewaltig bei der Verbesserung meiner Internetpräsenz helfen! Ohne ihn war meine Seite nicht einmal indexiert, er hat sich merklich in mein Thema eingearbeitet und schnell Lösungen gefunden, die mir massiv helfen konnten. Jetzt stehe ich seit Monaten in den Top3-Ergebnissen meiner Suchbegriffe, ohne Noah wäre das nicht möglich gewesen und ich kann ihn zu 100% empfehlen! Vielen Dank für deine Ideen, deine Geduld und die tollen Ergebnisse für mein Unternehmen!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Von Anfang an war die Zusammenarbeit mit Noah Lutz eine absolute Bereicherung für unser Online-Geschäft. Als wir uns auf die Suche nach einem SEO-Spezialisten machten, um die Sichtbarkeit unserer Website in den Google-Suchergebnissen zu verbessern, stießen wir auf zahlreiche Anbieter. Die Entscheidung für Noah Lutz fiel uns jedoch leicht, sobald wir das erste Beratungsgespräch geführt hatten. Seine Professionalität, tiefgreifendes Fachwissen und die Fähigkeit, komplexe SEO-Konzepte verständlich zu erklären, haben uns sofort überzeugt. Noah Lutz hat sich die Zeit genommen, unser Geschäftsmodell und unsere Ziele gründlich zu verstehen. Er entwickelte eine maßgeschneiderte SEO-Strategie, die nicht nur auf die Verbesserung unserer Rankings abzielte, sondern auch darauf, qualitativ hochwertigen Traffic auf unsere Seite zu lenken. Durch die Implementierung gezielter Keyword-Recherchen, On-Page-Optimierung und den Aufbau einer soliden Backlink-Struktur konnten wir innerhalb weniger Monate signifikante Verbesserungen in den Suchergebnissen feststellen. Besonders beeindruckt hat uns die transparente Arbeitsweise von Noah Lutz. Er hat uns regelmäßig mit detaillierten Berichten und Analysen versorgt, die den Fortschritt unserer SEO-Maßnahmen aufzeigten. Seine proaktive Kommunikation und Bereitschaft, Fragen zu beantworten und Anpassungen vorzunehmen, wenn nötig, haben die Zusammenarbeit sehr angenehm gestaltet. Dank Noah Lutz haben wir nicht nur eine verbesserte Online-Präsenz erreicht, sondern auch ein tieferes Verständnis für die Bedeutung und Funktionsweise von SEO gewonnen. Seine Dienstleistungen haben sich als eine wertvolle Investition in die Zukunft unseres Unternehmens erwiesen. Für jedes Unternehmen, das seine Online-Sichtbarkeit ernsthaft verbessern möchte, kann ich Noah Lutz uneingeschränkt empfehlen. Seine Expertise, sein Engagement und seine Ergebnisse sprechen für sich. Wir freuen uns auf eine weiterhin erfolgreiche Zusammenarbeit.Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Wir sind äußerst zufrieden mit der knapp einjährigen Zusammenarbeit mit Noah Lutz. Seine fundierten SEO-Kenntnisse haben maßgeblich zur Stärkung der Online-Präsenz des Unternehmens beigetragen. Professionelle Zusammenarbeit, transparente Berichterstattung und nachweisliche Ergebnisse machen Herrn Lutz zu einem empfehlenswerten Partner für erfolgreiches Online-Marketing. Vielen Dank für die hervorragende Arbeit!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Super empfehlenswert! Wir arbeiten schon länger mit Herr Lutz zusammen und die Qualität sowie die Ergebnisse stimmen einfach!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Herr Lutz ist sehr kompetent, seine Erklärungen sind hilfreich, er arbeitet sehr schnell und setzt Wünsche und besprochene Maßnahmen rasch um. Das Ranking-Ergebnis für meine Webseite hat sich klar verbessert. Ich freue mich auf die weitere Zusammenarbeit.Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Deine Unterstützung war Gold wert, danke dir!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Normalerweise setzen wir Auftrag und Erledigung in der Dienstleistung als eine ganz normale Sache voraus,aber in Ihrem Falle haben Sie mehr geleistet als abgesprochen. Genau dieses hebt Sie hervor. Vielen Dank hierfür Herr Lutz. Firma F&H Läufle GmbH
Wie funktioniert eine Robots.txt?
Die Funktion einer Robots.txt-Datei ist entscheidend für die Steuerung des Zugriffs von Webcrawlern auf Ihre Webseite. Diese einfache, aber mächtige Textdatei wird auf Ihrem Webserver gehostet und dient als Wegweiser für Bots, die Ihre Webseite durchsuchen. Wenn Sie möchten, dass bestimmte Seiten Ihrer Webseite nicht in Suchmaschinenergebnissen erscheinen, bietet die robots.txt-Datei eine effektive Methode, um dies zu steuern. Durch präzise Anweisungen wie ‚User-agent‘, ‚Disallow‘ und ‚Allow‘ können Sie entscheiden, welcher Bot auf welche Teile Ihrer Webseite zugreifen darf. Beispielsweise blockiert ‚Disallow‘ den Zugriff auf bestimmte Seiten oder Verzeichnisse, während ‚Allow‘ den Zugriff auf ausgewählte Inhalte erlaubt, selbst wenn sie in einem ansonsten blockierten Bereich liegen. Diese Kontrolle gibt Ihnen die Möglichkeit, den Traffic auf Ihrer Webseite zu leiten und die Sichtbarkeit bestimmter Inhalte zu steuern.
Bots interpretieren die Anweisungen in Ihrer robots.txt-Datei mit erstaunlicher Effektivität. Beim Zugriff auf Ihre Webseite suchen sie zunächst nach dieser Datei im Stammverzeichnis. Die darin enthaltenen Anweisungen sind entscheidend, da sie bestimmen, welche Seiten durchsucht und indexiert werden dürfen. Seiten, die durch ‚Disallow‘ markiert sind, bleiben vor neugierigen Crawlern geschützt, während andere Inhalte frei zugänglich sind. Darüber hinaus bietet die robots.txt-Datei erweiterte Funktionen wie ‚Crawl-Delay‘, welches festlegt, wie lange ein Bot zwischen den Anfragen warten soll, um Ihren Server zu schonen. Ebenso kann ein Verweis auf die XML-Sitemap der Webseite den Bots helfen, Ihre Inhalte effizienter zu indexieren. Durch diese strategische Steuerung optimieren Sie nicht nur die Leistung Ihrer Webseite, sondern auch deren Sichtbarkeit und Relevanz in den Suchmaschinenergebnissen.

Kostenloses Erstgespräch
Noah Lutz
SEO & SEA Spezialist

unverbindliche Beratung
persönlicher Ansprechpartner & flexible Laufzeiten
Konkrete Analyse und Strategievorstellung nach Erstgespräch
In einem Erstgespräch haben wir die Gelegenheit, uns persönlich kennenzulernen. Dabei gebe ich Ihnen einen Einblick in meine Arbeitsweise, während ich mehr über Sie und Ihr Projekt erfahre. Im Anschluss an das Gespräch erhalten Sie ein unverbindliches Angebot, das eine konkrete Analyse und Strategievorstellung für Ihr Projekt umfasst.
Die Rolle der Robots.txt beim SEO
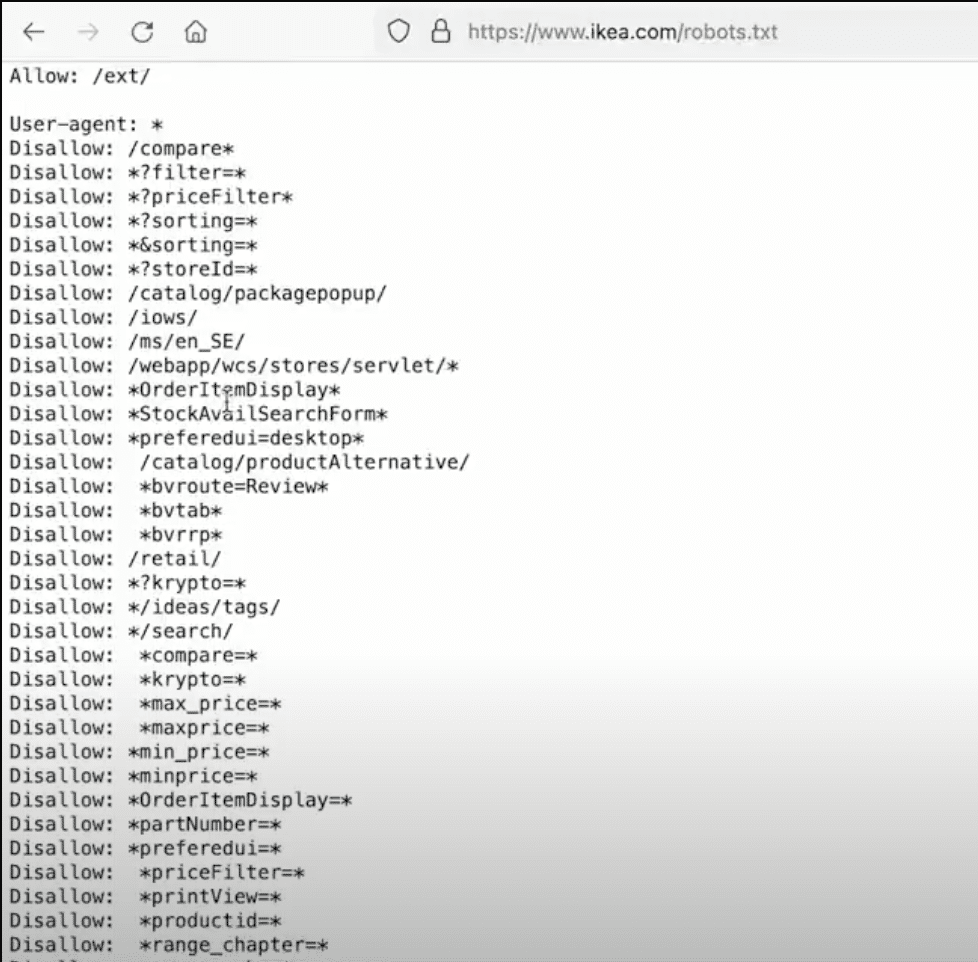
Die robots.txt-Datei ist ein essenzielles Werkzeug in der Suchmaschinenoptimierung (SEO) und ermöglicht Ihnen als Website-Betreiber, Kontrolle über die Indexierung Ihrer Website zu erlangen. Durch die gezielte Steuerung, welche Bereiche Ihrer Website von Suchmaschinen-Crawlern durchsucht werden dürfen, können Sie sicherstellen, dass nur relevante und wichtige Inhalte indexiert werden. Dies ist besonders entscheidend, um die Qualität Ihres Indexes zu verbessern und die Sichtbarkeit Ihrer Website in den Suchergebnissen zu erhöhen. Beispielsweise können Sie durch die Blockierung irrelevanter oder doppelter Seiten wie Admin-Bereiche oder Testseiten die Suchmaschinen darauf fokussieren, ausschließlich wertvolle Inhalte zu berücksichtigen. Indem Sie den Zugang zu bestimmten Verzeichnissen kontrollieren, bieten Sie den Suchmaschinen eine klare Struktur Ihrer Website, was letztendlich zu einer verbesserten Platzierung führen kann.

Ein weiterer bedeutender Aspekt der robots.txt-Datei ist die Vermeidung von Duplicate Content, der ansonsten Ihre Suchmaschinen-Rankings negativ beeinflussen könnte. Durch die Blockierung doppelter Inhalte, die möglicherweise von unterschiedlichen URLs abrufbar sind, verhindern Sie Verwirrung bei den Suchmaschinen darüber, welche Version einer Seite angezeigt werden soll. Auf diese Weise beugen Sie negativen Auswirkungen auf Ihr Ranking vor und stellen sicher, dass Ihre Website einheitlich und klar präsentiert wird. Darüber hinaus trägt die robots.txt-Datei zur Optimierung der Crawling-Effizienz bei, indem sie den Bots die Möglichkeit gibt, sich auf die wichtigsten Seiten Ihrer Website zu konzentrieren. Eine wohlüberlegte Einrichtung der Datei kann dazu führen, dass Suchmaschinen-Ressourcen effizienter genutzt werden und Ihre wichtigsten Inhalte schneller indexiert werden, was wiederum zu einer schnelleren Aktualisierung der Suchergebnisse führen kann. Nutzen Sie daher die Leistungsfähigkeit der robots.txt-Datei, um Ihre Website optimal für Suchmaschinen zu positionieren und Ihre SEO-Strategie zu stärken.
Aufbau von Protokollen in der Robots.txt
Wenn Sie die Sichtbarkeit und Zugänglichkeit Ihrer Website für Suchmaschinen optimieren möchten, ist die robots.txt-Datei ein unverzichtbares Werkzeug. Dieses leistungsstarke Protokoll hilft Ihnen dabei, gezielt zu steuern, welche Teile Ihrer Website von Webcrawlern indiziert werden dürfen. Das Robots Exclusion Standard Protokoll legt fest, dass Suchmaschinen-Robots zuerst im Root-Verzeichnis nach einer Datei mit der Bezeichnung robots.txt suchen. Diese Datei enthält Gruppen von Anweisungen, die präzise festlegen, welche Bereiche einer Website durchsuchbar sind und welche nicht.
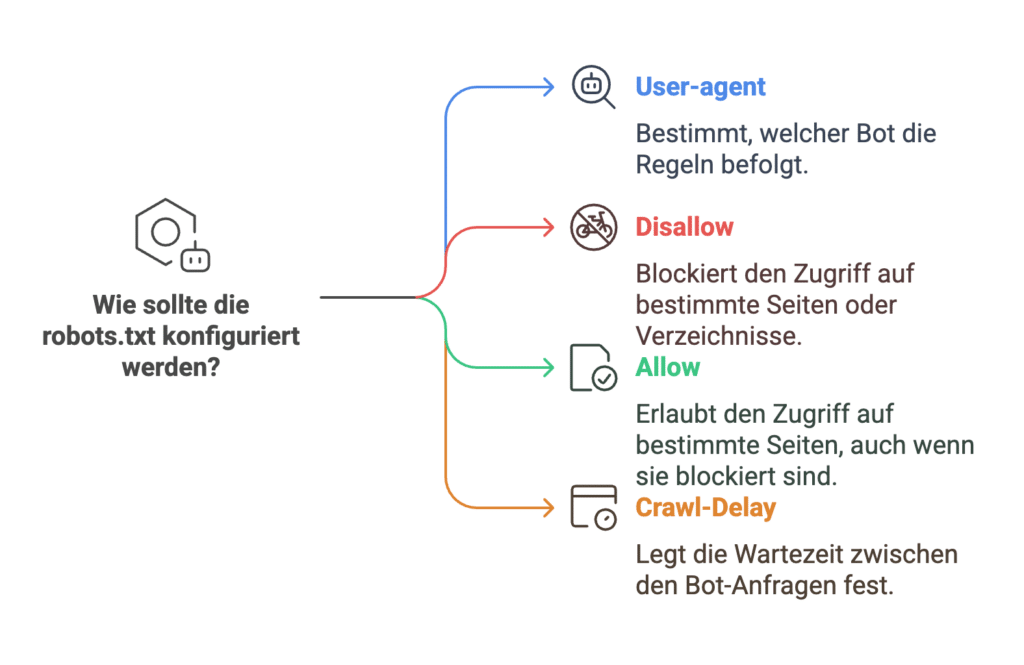
Die robots.txt-Datei ist so strukturiert, dass sie mehrere Regeln oder Anweisungen enthält, die zeilenweise aufgelistet werden. Jede Gruppe beginnt mit einer User-agent-Zeile. Diese bestimmt, für welchen Webcrawler die nachfolgenden Anweisungen gelten. Die Flexibilität der robots.txt-Datei ermöglicht es Ihnen, den Zugriff auf spezifische Verzeichnisse oder Dateien entweder zu erlauben oder zu verbieten. Neben dem Hauptprotokoll, dem Robots Exclusion Protocol, verwenden robots.txt-Dateien auch das Sitemaps-Protokoll, das auf die XML-Sitemaps verweist und sicherstellt, dass ein Crawler keine wichtigen Seiten übersieht.
Nachfolgend finden Sie eine übersichtliche Tabelle, die die wesentlichen Komponenten einer robots.txt-Datei zusammenfasst:
| Element | Zweck | Syntax | Beispiel |
|---|---|---|---|
User-agent | Gibt an, für welchen Bot die Anweisungen gelten. |
|
gilt für alle Bots. |
gilt speziell für den Google-Bot. | |||
Disallow | Blockiert den Zugriff auf bestimmte Seiten oder Verzeichnisse. |
|
blockiert den Zugriff auf /private/. |
blockiert den Zugriff auf /tmp/. | |||
Allow | Erlaubt den Zugriff auf bestimmte Seiten oder Verzeichnisse, auch wenn sie in einem blockierten Bereich liegen. |
|
erlaubt Zugriff auf /public/. |
Crawl-Delay | Gibt an, wie viele Sekunden ein Bot zwischen den Anfragen warten soll, um die Serverlast zu reduzieren. |
|
bedeutet, dass der Bot 5 Sekunden wartet. |
Ausschluss von URL’s aus dem Index über die Robots.txt Datei
Ausschluss von URLs aus dem Index über die robots.txt-Datei kann für Unternehmen ein wichtiges Instrument zur Steuerung des Website-Crawlings sein, jedoch sollten Sie sich bewusst sein, dass die robots.txt-Datei keine Garantie dafür bietet, dass ausgeschlossene URLs tatsächlich nicht indexiert werden. Einige Suchmaschinen halten sich möglicherweise nicht an die in der Datei enthaltenen Anweisungen, was bedeutet, dass stark verlinkte Inhalte trotz Ausschluss dennoch ihren Weg in den Index finden können. Daher ist es entscheidend, sich nicht ausschließlich auf die robots.txt zu verlassen, wenn es darum geht, die Indexierung von bestimmten Seiten zu verhindern. Eine effektivere Methode besteht darin, den meta-robots-Tag mit der Anweisung „noindex“ direkt im HTML-Quelltext der betreffenden Seite zu verwenden. Dies stellt sicher, dass die Seiten, die Sie vor der Indexierung schützen möchten, von den meisten Suchmaschinen respektiert werden. Während Disallow-Befehle in der robots.txt hilfreich sein können, um doppelten Inhalt auszuschließen, bieten sie keine absolute Sicherheit. Denken Sie daran, dass die Einhaltung der Regeln von der jeweiligen Suchmaschine abhängt, und deshalb sollten Sie eine umfassende Strategie entwickeln, um Ihre Inhalte effizient und sicher zu verwalten.
FAQ: Häufig gestellte Fragen und Antworten zur Robots.txt
Welche Rolle spielt die Robots.txt-Datei in der Suchmaschinenoptimierung?
Die Robots.txt-Datei steuert, welche Seiten von Suchmaschinen gecrawlt werden, und kann so die Indexierung und Sichtbarkeit einer Website beeinflussen.
Wie kann man sicherstellen, dass die Robots.txt-Datei korrekt implementiert ist?
Man sollte die Syntax überprüfen, die Datei im Stammverzeichnis platzieren und Tools wie die Google Search Console nutzen, um Fehler zu identifizieren.
Welche Inhalte sollten in der Robots.txt-Datei blockiert werden, und welche nicht?
Blockiert werden sollten sensible oder doppelte Inhalte, während wichtige Seiten für die Indexierung zugänglich bleiben sollten.
Wie wirkt sich eine fehlerhafte Robots.txt-Datei auf die Indexierung einer Website aus?
Eine fehlerhafte Datei kann dazu führen, dass wichtige Seiten nicht indexiert oder falsche Seiten blockiert werden, was die Sichtbarkeit beeinträchtigt.
Gibt es Alternativen zur Robots.txt-Datei, um den Zugriff von Bots zu kontrollieren?
Ja, z. B. Meta-Tags wie noindex oder nofollow sowie serverseitige Zugriffsbeschränkungen.
Wie kann man bösartige Bots effektiv blockieren, wenn Robots.txt nicht ausreicht?
Man kann Firewalls, IP-Blocklisten oder spezielle Sicherheitssoftware verwenden, um bösartige Bots abzuwehren.
Welche Tools und Ressourcen sind hilfreich, um die Robots.txt-Datei zu überprüfen und zu optimieren?
Tools wie die Google Search Console, Screaming Frog oder Online-Syntax-Checker sind nützlich für die Überprüfung und Optimierung.
Persönliche Erfahrung mit der Robots.txt
Ich persönlich habe in meiner täglichen Arbeit als SEO Spezialist habe ich ehrlicherweise wenig Berührungspunkte mit der Robots.txt Datei. Da meist durch die CMS Systeme automatisch eine solche Datei erstellt wird und die Steuerung darüber für die wenigsten Webseiten von großer Relevanz ist. Die Datei sollte aber in jedem Fall existieren.



